Spark Streaming + Kinesis Integration Amazon Kinesis is a fully managed service for real-time processing of streaming data at massive scale. The Kinesis receiver creates an input DStream using the Kinesis Client Library (KCL) provided by Amazon under the Amazon Software License (ASL). Spark Streaming is an extension of the core Spark framework that enables scalable, high-throughput, fault-tolerant stream processing of data streams such as Amazon Kinesis Streams. Spark Streaming provides a high-level abstraction called a Discretized Stream or DStream, which represents a continuous sequence of RDDs.

Optimize SparkStreaming to Efficiently Process Amazon Kinesis Streams AWS Big Data Blog
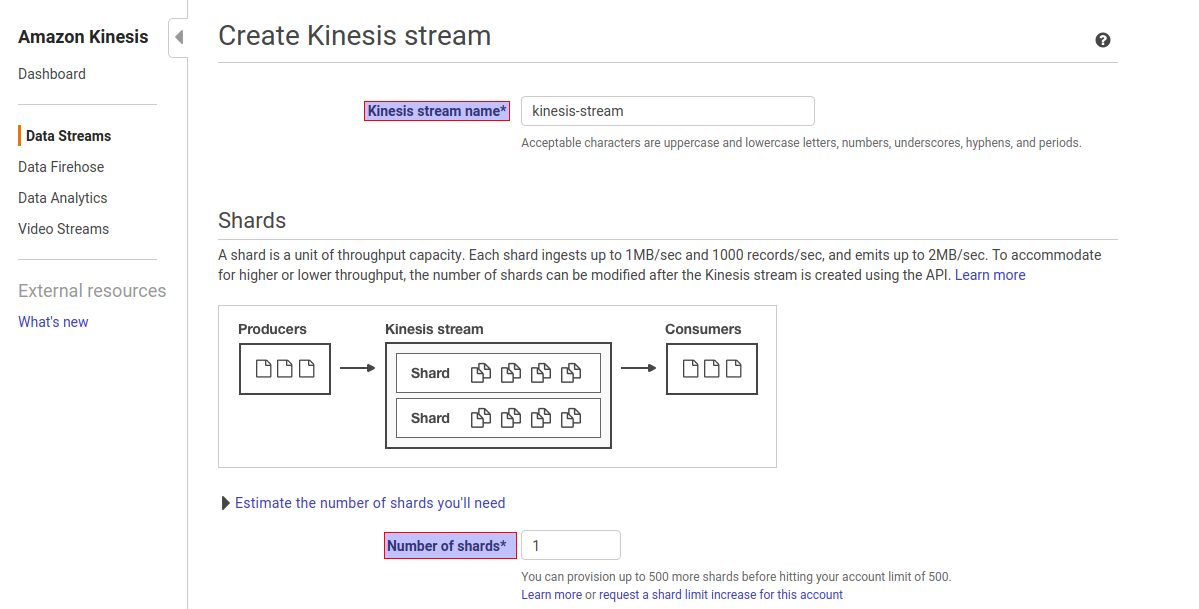
Spark Streaming is the previous generation of Spark's streaming engine. There are no longer updates to Spark Streaming and it's a legacy project. There is a newer and easier to use streaming engine in Spark called Structured Streaming. You should use Spark Structured Streaming for your streaming applications and pipelines. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of batched results. For more information, see the Spark Streaming Programming Guide. PDF RSS Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. For more information on consuming Kinesis Data Streams using Spark Streaming, see Spark Streaming + Kinesis Integration. Step1. Go to Amazon Kinesis console -> click on Create Data Stream Step2. Give Kinesis Stream Name and Number of shards as per volume of the incoming data. In this case, Kinesis stream name as kinesis-stream and number of shards are 1. Shards in Kinesis Data Streams A shard is a uniquely identified sequence of data records in a stream.
Processing Kinesis Data Streams with Spark Streaming
Apache Spark's Structured Streaming with Amazon Kinesis on Databricks by Jules Damji August 9, 2017 in Company Blog Share this post On July 11, 2017, we announced the general availability of Apache Spark 2.2.0 as part of Databricks Runtime 3.0 (DBR) for the Unified Analytics Platform. Spark Structured Streaming is a high-level API built on Apache Spark that simplifies the development of scalable, fault-tolerant, and real-time data processing applications. By seamlessly. I modified this example and used my own values for "app-name", "stream-name" and "endpoint-url". I have placed various print lines within my code. When running the job using the cmd "spark-submit" I fail to see any print lines in the stdout logs. Can someone please explain to me where I can find the system out print lines. Apache Spark version 2.0 introduced the first version of the Structured Streaming API which enables developers to create end-to-end fault tolerant streaming jobs. Although the Structured.

Spark Streaming with Kafka Example Spark By {Examples}
Spark Streaming + Kinesis Integration Amazon Kinesis is a fully managed service for real-time processing of streaming data at massive scale. The Kinesis receiver creates an input DStream using the Kinesis Client Library (KCL) provided by Amazon under the Amazon Software License (ASL). This Spark Streaming with Kinesis tutorial intends to help you become better at integrating the two. In this tutorial, we'll examine some custom Spark Kinesis code and also show a screencast of running it. In addition, we're going to cover running, configuring, sending sample data and AWS setup.
Here we explain how to configure Spark Streaming to receive data from Kinesis. Configuring Kinesis A Kinesis stream can be set up at one of the valid Kinesis endpoints with 1 or more shards per the following guide. Configuring Spark Streaming Application For more information, see Example: Read From a Kinesis Stream in a Different Account. AWS Glue streaming ETL jobs can auto-detect compressed data, transparently decompress the streaming data, perform the usual transformations on the input source, and load to the output store.. Choose Spark streaming.
Processing Kinesis Data Streams with Spark Streaming
Feb 26, 2021 -- This tutorial describes a real time analytics frame work using spark streaming and window functions on AWS real time streaming application Kinesis. Amazon Kinesis Data. We will do the following steps: create a Kinesis stream in AWS using boto3 write some simple JSON messages into the stream consume the messages in PySpark display the messages in the console TL;DR: Github code repo Step 1: Setup PySpark for Jupyter In order to be able to run PySpark in the notebook, we have to use the findspark package.
